Machine learning model management¶
By default, CodeScoring uses its own machine learning model to reduce the number of false positives when searching for secrets. By manually marking the found secrets, you can further train the model and improve the search results on your own source code.
To further train the model, go to the Settings -> Workmode section and click the Run now button in the Secrets ML model management section. To activate the ability to further train the model, it is necessary to mark up at least 1000 found secrets as true positives or false positives.
After further training, you can compare the results of the secret search and, based on them, either accept the user model (Accept training) or return to the base model (Purge user model).
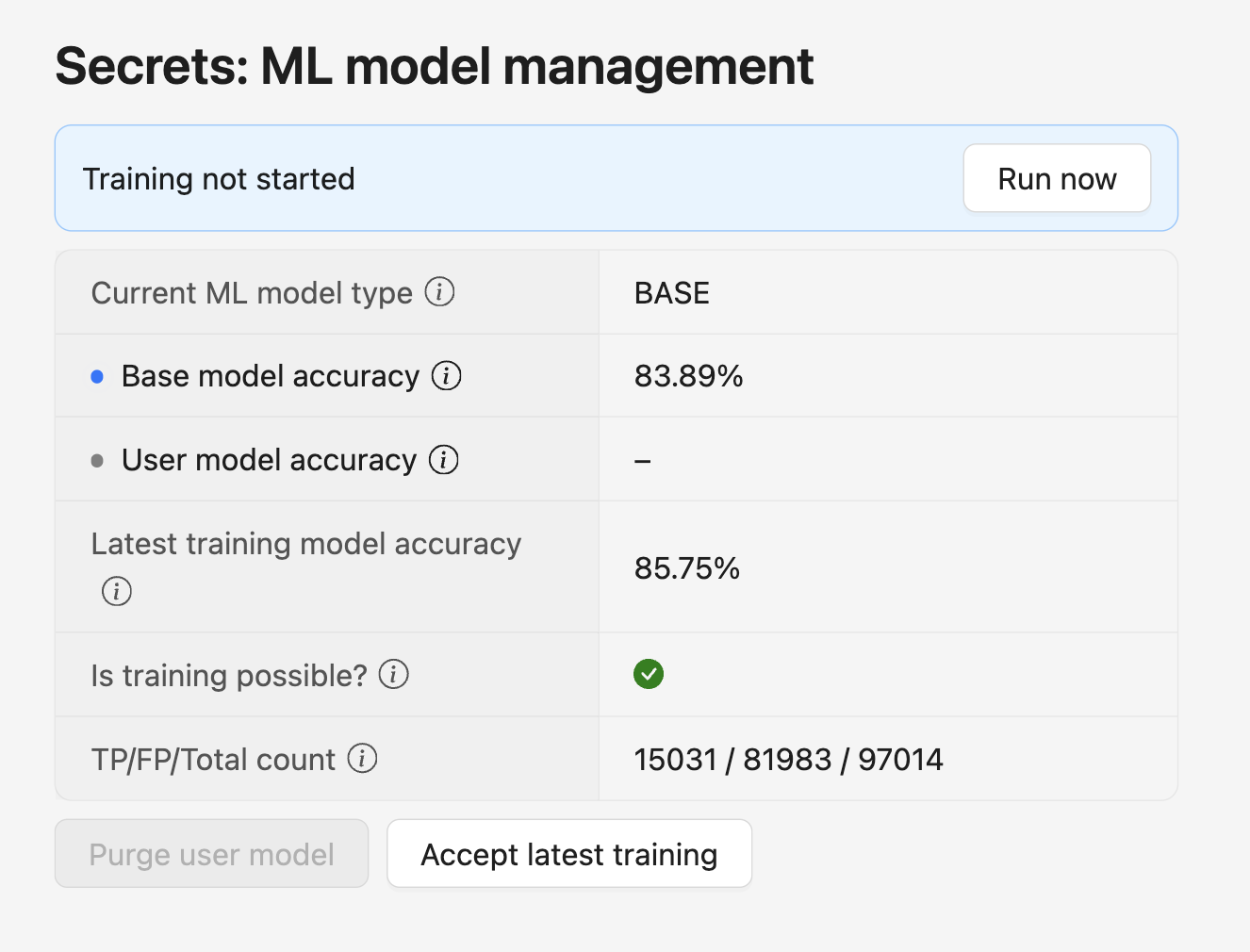
The control section displays information about the current state of the model to the user:
- Current ML Model Type – type of the model used (base or user);
- Base model accuracy – search accuracy based on marked findings. True positive findings are taken as 1, false positive findings as 0. The final accuracy is the average value of all results, presented as a percentage;
- User model accuracy – search accuracy using the user model;
- Latest training model accuracy – search accuracy using the latest additional training;
- Is training possible – possibility of additional training of the model based on the current labeling;
- TP/FP/Total count – true positives, false positives and all findings.
Important: if additional training of the model is impossible, this means that the markup is not complete enough. In this case, it is necessary to designate a larger number of findings as true positives or false positives.